In our research on long-tail music recommendation, we have come across three distinct forms of popularity bias:
- Popularity-Related Degradation: a decrease in recommender system performance as a function of lower item popularity
- Popular Item Feedback Advantage: popular items tend to have more user feedback associated with them
- Popularity Lift: the difference in popularity between items in the user’s profile (i.e., the inputs) and items that are recommended to the user (the outputs)
In this post, we will discuss all three and describe some of our recent findings from ISMIR 2022 and ACM RecSys 2023.
Details:
The core research problem that we explore in our Localify.org project is long-tail music artist recommendation. Our current database of about 1.5M artists. For 40K “local” artists (artists for which we know their origin), the median Spotify popularity is 22 out of 100. For the 100K “touring” artists, (artists who have had one or more live events in the past two years), the median Spotify popularity is 16 out of 100. This suggests that most of the artists that we are interested in recommending are relatively unpopular and can be considered long-tail artists.
| # artists | 25% | 50% | 75% | 95% | |
| “Local Artists” – (known origin) | 41,526 | 5 | 22 | 35 | 54 |
| “Touring” Artists – (one or more shows in 2022-23) | 99,276 | 3 | 16 | 33 | 52 |
When exploring the task of long-tail item recommendation, the concept of popularity bias naturally arises. However, this term is overloaded in that there are at least three different (but related) versions of popularity bias.
Popularity-related degradation
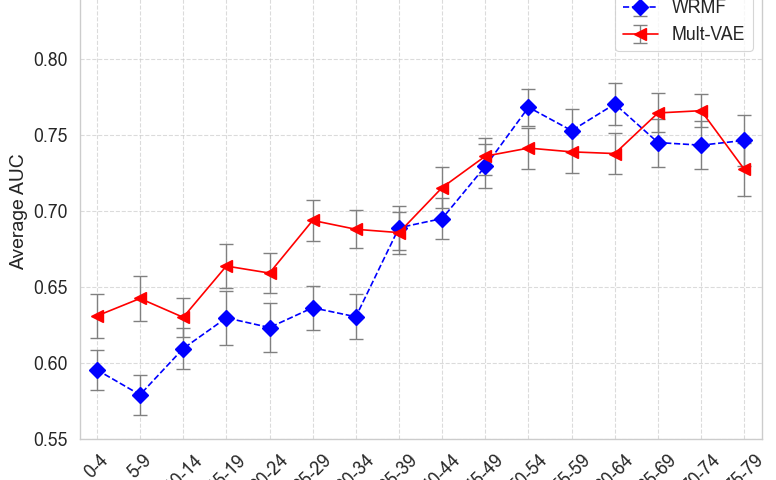
The first popularity bias, which we refer to as popularity-related degradation, relates to a decrease in recommender system performance as a function of lower item popularity. [See Steck 2011.] In our recent ACM RecSys workshop paper, we explore degradation bias by comparing two standard recommendation algorithms (WRMF, Mult-VAE) in terms of being able to recommend artists with varying levels of popularity. If we limit the artists we want to recommend to a certain Spotify popularity range, say 20 to 24 out of 100, we calculate how good each algorithm is at recommending artists for this level of artist popularity.
While you would have to read our paper to see the details of our experimental design, the two main takeaways from our plot on the right are that
- You can observe that both WRMF and Mult-VAE are susceptible to popularity-related degradation since the relative performance increases as a function of artist popularity.
- Mult-VAE outperforms WRMF at lower levels of popularity and, as a result, is better suited for the task of long-tail local artist recommendation
This is preliminary work and our experimental design has a number of limitations. However, we are excited about this research since it can provide a methodology for evaluating recommender systems for the specific task of local music recommendation.
Popular item feedback advantage
The second form of popularity bias is popular item feedback advantage in which popular items tend to have more user feedback (ratings, streams, clicks) associated with them. These first two versions of popularity bias are related in that recommender systems tend to be optimized per unit of feedback (e.g., each user-item interaction), and since popular items are associated with more feedback, an algorithm that does better on popular items will perform better overall.
This kind of popularity bias is not a direct problem for Localify right now since we use an artist-artist similarity matrix instead of a user-artist matrix which is the typical input to a recommendation algorithm. This is because we don’t have much of our own user data (yet!) and artist-artist similarity data is readily available using both music data APIs. (e.g., Spotify or Last.fm are two good music data APIs with artist similarity information.)
Popularity Lift
The third version of popularity bias, called popularity lift, is related to the difference in popularity between items in the user’s profile (i.e., the inputs) and items that are recommended to the user (the outputs) [See the work of Abdollahpouri et al. 2019]. The intuition is that if we think of recommender systems as traversing a graph of (embedded) items and users, there are more paths to the popular items. This can be pernicious in that it can contribute to a rich-get-richer cultural marketplace in which popular items crowd out less popular items that might be of more value to the user. Crowding out is especially important in the music domain because of the mere exposure effect in which listeners have to first become familiar with the music before they will appreciate it.
One thing we were curious about was how much popularity lift bias there was in commercial streaming services. We conducted a study where we simulated new users on different music streaming services (Spotify, Amazon Music, YouTube). We seed a user with low, medium, and high popular artists and then record which artists were recommended back to the simulated user.
To our surprise, we did not observe any popularity lift from the automatically generated personalized playlists on any streaming music services. However, this is not to say that streaming services are not responsible for creating the extreme “rich get richer” marketplace. Instead, we think that this may be created by the popular human-curated playlists that are maintained by editors from the steaming services or companies related to the major record labels. Luis Aguilar has done excellent work on measuring the actual value in dollars of having a song get placed on one of these high-profile playlists. It is big business so it is not surprising that less popular, independent artists may be being crowded out since they do not have the knowledge or connections to compete.
Why It Matters
Our goal for Locality is to explore all three forms of popularity bias so that local artists have a fair chance to compete for the listener’s attention. In addition, users are more likely to prefer an artist after they have seen them live. If we recommend (less popular) local artists who play inexpensive shows at nearby venues, the user may find value in a recommender system that recommends these artists over (mainstream) non-local artists they typically might listen to.